





11月17日,上海人工智能實驗室聯合商湯科技SenseTime、香港中文大學、上海交通大學共同發布新一代通用視覺技術體系「書生」(INTERN),該體系旨在系統化解決當下人工智能視覺領域中存在的任務通用、場景泛化和數據效率等一系列瓶頸問題。目前技術報告已在arXiv平台發布(https://arxiv.org/abs/2111.08687),基於「書生」的通用視覺開源平台OpenGVLab也將在明年年初正式開源,向學術界和產業界公開預訓練模型及其使用范式、數據系統和評測基準等。OpenGVLab將與上海人工智能實驗室此前發布的OpenMMLab一道,共同構築開源體系OpenXLab,助力通用人工智能的基礎研究和生態構建。

上海人工智能實驗室聯合商湯科技、香港中文大學、上海交通大學共同發布新一代通用視覺技術體系「書生」(INTERN)
任務通用和數據學習效率是制約當前人工智能發展的核心瓶頸問題。根據相關技術報告,一個「書生」基模型即可全面覆蓋分類、目標檢測、語義分割、深度估計四大視覺核心任務。在ImageNet等26個最具代表性的下游場景中,書生模型廣泛展現了極強的通用性,顯著提升了這些視覺場景中長尾小樣本設定下的性能。
相較于當前最強開源模型(OpenAI于2021年發布的CLIP),「書生」在準確率和數據使用效率上均取得大幅提升。具體而言,基於同樣的下游場景數據,「書生」在分類、目標檢測、語義分割及深度估計四大任務26個數據集上的平均錯誤率分別降低了40.2%、47.3%、34.8%和9.4%。「書生」在數據效率方面的提升尤為令人矚目:只需要1/10的下游數據,就能超過CLIP(openai.com/blog/clip)基於完整下游數據的準確度,例如在花卉種類識別FLOWER任務上,每一類只需兩個訓練樣本,就能實現99.7%的準確率。
隨着人工智能賦能產業的不斷深入,人工智能系統正在從完成單一任務向複雜的多任務協同演進,其覆蓋的場景也越來越多樣化。在自動駕駛、智能製造、智慧城市等眾多的長尾場景中,數據獲取通常困難且昂貴,研發通用人工智能模型,對於降低數據依賴尤為重要。而突破「工業應用紅線」的模型,需滿足同時完成多任務、覆蓋大量長尾場景,且基於下游小樣本數據進行再訓練等要求。上海人工智能實驗室、商湯科技、港中文以及上海交大聯合推出的「書生」通用視覺技術體系,體現了產學研合作在通用視覺領域的全新探索,為走向通用人工智能邁出堅實一步。借助「書生」通用視覺技術體系,業界可憑借極低的下游數據採集成本,快速驗證多個新場景,對於解鎖實現人工智能長尾應用具有重要意義。
「當前發展通用視覺的核心,是提升模型的通用泛化能力和學習過程中的數據效率。面向未來,『書生』通用視覺技術將實現以一個模型完成成百上千種任務,體系化解決人工智能發展中數據、泛化、認知和安全等諸多瓶頸問題。」上海人工智能實驗室主任助理喬宇表示。
商湯科技研究院院長王曉剛表示,「『書生』通用視覺技術體系是商湯在通用智能技術發展趨勢下前瞻性布局的一次嘗試,也是SenseCore商湯AI大裝置背景下的一次新技術路徑探索。『書生』承載了讓人工智能參與處理多種複雜任務、適用多種場景和模態、有效進行小數據和非監督學習並最終具備接近人的通用視覺智能的期盼。希望這套技術體系能夠帮助業界更好地探索和應用通用視覺AI技術,促進AI規模化落地。」

書生(INTERN)在分類、目標檢測、語義分割、深度估計四大任務26個數據集上,基於同樣下游場景數據(10%),相較于最強開源模型CLIP-R50x16,平均錯誤率降低了40.2%,47.3%,34.8%,9.4%。同時,書生只需要10%的下游數據,平均錯誤率就能全面低於完整(100%)下游數據訓練的CLIP。
階梯式學習:七大模塊打造全新技術路徑

書生(INTERN)技術體系可以讓AI模型處理多樣化的視覺任務
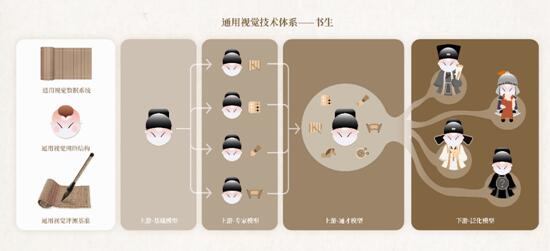
通用視覺技術體系「書生」(INTERN)由七大模塊組成,包括通用視覺數據系統、通用視覺網絡結構、通用視覺評測基準三個基礎設施模塊,以及區分上下游的四個訓練階段模塊。
書生作為中國古代讀書人的經典形象,代表着一個通過不斷學習、不斷成長進而擁有各方面才能的人格化角色:從基礎的知識技能學習開始,到對多種專業知識觸類旁通,進而成長為擁有通用知識的通才。將全新的通用視覺技術體系命名為「書生」,意在體現其如同書生一般的特質,可通過持續學習,舉一反三,逐步實現通用視覺領域的融會貫通,最終實現靈活高效的模型部署。
當前的AI系統開發模式下,一個AI模型往往只擅長處理一項任務,對於新場景、小數據、新任務的通用泛化能力有限,導致面對千變萬化的任務需求時,須獨立開發成千上萬種AI模型。同時,研究人員每訓練一個AI模型,都需構建標注數據集進行專項訓練,並持續進行權重和參數優化。這種低效的學習訓練方法,導致人力、時間和資源成本居高不下,無法實現高效的模型部署。
「書生」的推出能夠讓業界以更低的成本獲得擁有處理多種下游任務能力的AI模型,並以其強大的泛化能力支撐智慧城市、智慧醫療、自動駕駛等場景中大量小數據、零數據等樣本缺失的細分和長尾場景需求。
通用視覺技術體系「書生」(INTERN)由七大模塊組成,包括3個基礎設施模塊、4個訓練階段模塊
持續成長:「四階段」提升通用泛化
在「書生」(INTERN)的四個訓練階段中,前三個階段位於該技術鏈條的上游,在模型的表征通用性上發力;第四個階段位於下游,可用於解決各種不同的下游任務。
第一階段,着力于培養「基礎能力」,即讓其學到廣泛的基礎常識,為後續學習階段打好基礎;第二階段,培養「專家能力」,即多個專家模型各自學習某一領域的專業知識,讓每一個專家模型高度掌握該領域技能,成為專家;第三階段,培養「通用能力」,隨着多種能力的融會貫通,「書生」在各個技能領域都展現優異水平,並具備快速學會新技能的能力。
在循序漸進的前三個訓練階段模塊,「書生」在階梯式的學習過程中具備了高度的通用性。當進化到第四階段時,系統將具備「遷移能力」,此時「書生」學到的通用知識可以應用在某一個特定領域的不同任務中,如智慧城市、智慧醫療、自動駕駛等,實現廣泛賦能。
產學研協同:開源共創通用AI生態
作為AI技術的下一個重大里程碑,通用人工智能技術將带來顛覆性創新,實現這一目標需要學術界和產業界的緊密協作。上海人工智能實驗室、商湯科技、港中文以及上海交大未來將依托通用視覺技術體系「書生」(INTERN),發揮產學研一體化優勢,為學術研究提供平台支持,並全面賦能技術創新與產業應用。
明年年初,基於「書生」的通用視覺開源生態OpenGVLab將正式開源,向學術界和產業界公開預訓練模型、使用范式和數據庫等,而全新創建的通用視覺評測基準也將同步開放,推動統一標準上的公平和準確評測。OpenGVLab將與上海人工智能實驗室此前發布的OpenMMLab、OpenDILab一道,共同構築開源體系OpenXLab,持續推進通用人工智能的技術突破和生態構建。





電話:(香港)852-2564 0768
(深圳)86-755-83518792 83517835 83518291
地址:香港九龍觀塘道332號香港商報大廈









